AI算力资源池化
AI算力资源池化人工智能(AI)做为产业变革的核心力量,不仅是技术创新,更是推动经济发展、社会进步、行业创新的重要驱动力。作为AI市场中的重要组成, 以 GPU、 FPGA 等为主的 AI 加速器市场发展也随之水涨船高。
由于缺乏高效经济的 AI 算力资源池化解决方案, 导致绝大部分企业只能独占式地使用昂贵的AI算力资源,带来居高不下的AI算力使用成本;由于缺少对异构算力硬件支持,用户不得不修改 AI 应用以适应不同厂商的 AI 算力硬件。 这会加剧 AI 应用开发部署复杂性、提高 AI 算力投入成本并导致供应商锁定。
GPU资源池化技术从初期的简单虚拟化,到资源池化,经历了四个技术演进阶段:
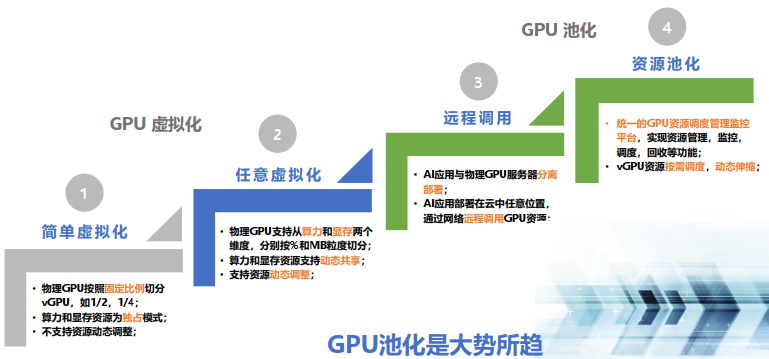
OrionX AI 算力资源池化解决方案已经实现了上述四个阶段的技术功能,可以为用户提供 GPU 资源池化的整体解决方案。
OrionX 帮助客户构建数据中心级 AI 算力资源池, 使用户应用无需修改就能透明地共享和使用数据中心内任何服务器之上的 AI 加速器。 OrionX 不但能够帮助用户提高 AI 算力资源利用率, 而且可以极大便利用户 AI 应用的部署。
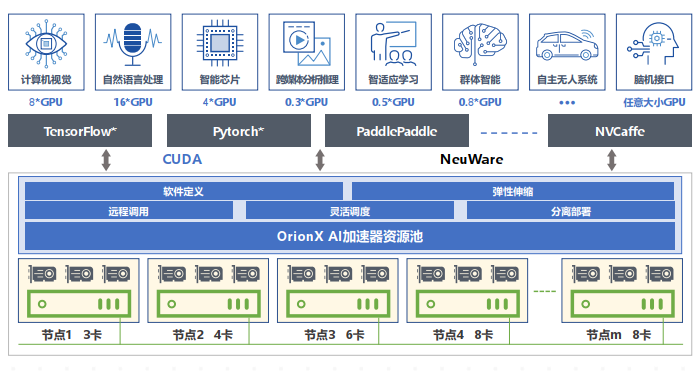
OrionX 通过软件定义AI算力,颠覆了原有的AI应用直接调用物理GPU的架构,增加软件层,将AI应用与物理GPU解耦合。AI应用调用逻辑的vGPU,再由OrionX将vGPU需求匹配到具体的物理GPU。OrionX 架构实现了GPU资源池化,让用户高效、智能、灵活地使用GPU资源,达到了降本增效的目的。
OrionX通过构建GPU资源池,让企业内的AI用户共享数据中心内所有服务器上的GPU算力。AI开发人员不必再关心底层资源状况,专注于更有价值的业务层面,让应用开发变得更加便捷。
提高利用率
支持将GPU切片为任意大小的vGPU,从而允许多AI负载并行运行,提高物理GPU利用率。
提高GPU综合利用率多达3-10倍,1张卡相当于起到N张卡的效果,真正做到昂贵算力平民化。
高性能
相比于物理GPU,OrionX本地vGPU性能损耗几乎为零,远程vGPU性能损耗小于 2%。
vGPU资源隔离,并行用户无资源互扰。
提高利用率
支持将GPU切片为任意大小的vGPU,从而允许多AI负载并行运行,提高物理GPU利用率。
提高GPU综合利用率多达3-10倍,1张卡相当于起到N张卡的效果,真正做到昂贵算力平民化。
轻松弹性扩展
支持从单台到整个数据中心GPU服务器纳管,轻松实现GPU资源池的横向扩展。
全分布式部署,通过RDMA(IB/RoCE)或 TCP/IP网络连接各个节点,实现资源池弹性扩展。
灵活调度
支持AI负载与GPU资源分离部署,更加高效合理地使用GPU资源。
CPU与GPU资源解耦合,两种服务器分开购买、按需升级、灵活调度,有助于最大化数据中心基础设施价值。
全局管理
提供GPU资源管理调度策略。
GPU全局资源池性能监控,为运维人员提供直观的资源利用率等信息。
对 AI 开发人员友好
一键解决AI开发人员面临的训练模型中GPU/CPU配比和多机多卡模型拆分问题,为算法工程师节省大量宝贵时间。
大模型场景如训练场景, 对算力资源需求量大, 通常会使用一张或者多张 GPU 卡资源。
作为 AI 算力资源池平台, OrionX 既可以支持单台服务器上的单卡、 多卡训练, 也可以支持跨设备的多卡训练。

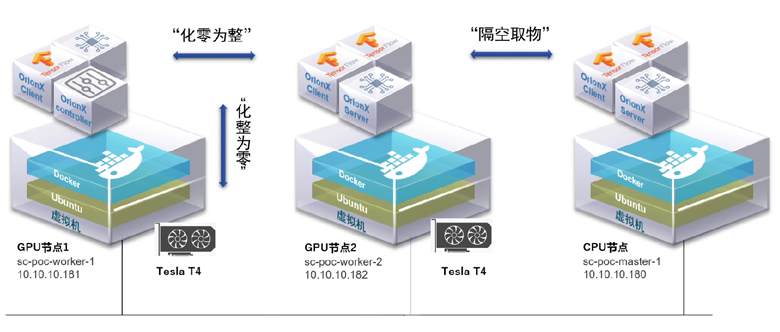
通过“化零为整”功能支持训练
支持将多台服务器上的 GPU 提供给一个虚拟机或者容器使用,而该虚拟机或者容器内的基于分布式训练框架(Horovod 或 Distributed Data Parallel)的 AI 应用无需修改代码。通过这个功能,用户可以将多台服务器的 GPU 资源聚合后提供给单一虚拟机或者容器使用。“化零为整”支持训练等大模型场景,为用户的 AI 应用提供数据中心级的海量算力。
通过“隔空取物”功能支持训练
支持将虚拟机或者容器运行在一台没有物理GPU的服务器上,通过计算机网络,透明地使用其他服务器上的GPU资源,该虚拟机或者容器内的 AI 应用无需修改代码。通过这个功能,OrionX 帮助用户实现了数据中心级的 GPU 资源池,实现了AI应用和GPU物理资源的解耦合,AI 应用在一个不满足训练条件的纯CUP服务器上,也一样能够快速调集多个GPU卡完成训练任务。